
ChatGPT: Commonly Asked Questions

Everything below was written in early March, 2023, and many of the details, numbers, and hyperlinks may be out of date by now.
We’ve had ChatGPT around for quite some time now, but many of us who work in or adjacent to AI still don’t have the complete picture of how or why it works the way it does. The following is an attempt to briefly answer a few commonly occurring questions [1] about the fastest growing consumer application to date.
Note that this writeup was originally written for a group of students taking an introductory class in modern AI, and so it assumes that the reader is fairly familiar with ChatGPT, at least from a user’s perspective. It also assumes familiarity with NLP terms that have entered common parlance these days, such as prompts, context, transformers, etc.
Though I have separated the content into seemingly independent questions, the answers to some of the questions do depend on understanding the answers to previous questions. Which is to say, feel free to skip to a question you’re interested in, but if something seems confusing, try reading through the first few questions and then try again.
I have tried to keep the article self contained, but have also sprinkled in several hyperlinks for any readers who feel like diving deeper into certain topics.
I’ve made sure to rely on primary sources (i.e. the original papers or statements by OpenAI) when it comes to factual claims. In cases where such a source was not sufficient, I have clearly mentioned the alternative source.
Note that while the focus of this document is on ChatGPT and the GPT models by OpenAI, much of the discussion is applicable to other GPT-like (decoder-based generative) language models as well.
Table of Contents
-
-
What changed on the road from GPT-1 > GPT-2 > GPT-3 > InstructGPT > ChatGPT?
-
How can ChatGPT understand / generate novel text that is not present in its training data?
-
How does ChatGPT remember what we’ve been talking about, and how much can it remember?
-
Does the order in which the task, instructions, context, etc. are provided in the prompt matter?
Questions
What exactly is the model architecture underlying ChatGPT?
ChatGPT is a variant of the GPT family of models, the other members of which are GPT-1 , GPT-2, GPT-3, and InstructGPT. [2]
If you go over to the ChatGPT homepage, you’ll learn the following:
-
ChatGPT is a sibling model to InstructGPT, and also
-
ChatGPT is fine-tuned from a model in the GPT-3.5 series, which finished training in early 2022.
Well, which is it?
The answer is, it’s both. If you go here to read what “GPT-3.5” means, you’ll find out that all text-generating GPT-3.5 models are just InstructGPT models (which themselves are just fine-tuned GPT-3 models), albeit with a fancy tag.
What changed on the road from GPT-1 > GPT-2 > GPT-3 > InstructGPT > ChatGPT?
There have been several key changes and improvements made to the GPT series of language models as they have evolved from GPT-1 to ChatGPT. They can be sorted into the following categories:
-
Scale: One of the most significant changes has been in the scale of the models. GPT-1 had 117 million parameters, while GPT-2 had 1.5 billion parameters, and GPT-3 increased this number to a whopping 175 billion parameters.
A common misconception (which I also shared prior to reading the InstructGPT paper) is that InstructGPT has only 1.3 billion parameters. In truth, there are versions of InstructGPT from 1.3 billion all the way to 175 billion parameters.
I couldn’t find a definitive source for the number of parameters in ChatGPT, so it could be anywhere from 1.3 billion to 175 billion parameters. My bet would be on 175B though, simply because larger models perform better than smaller models (all else being equal), as can be seen in the following image from the InstructGPT paper.
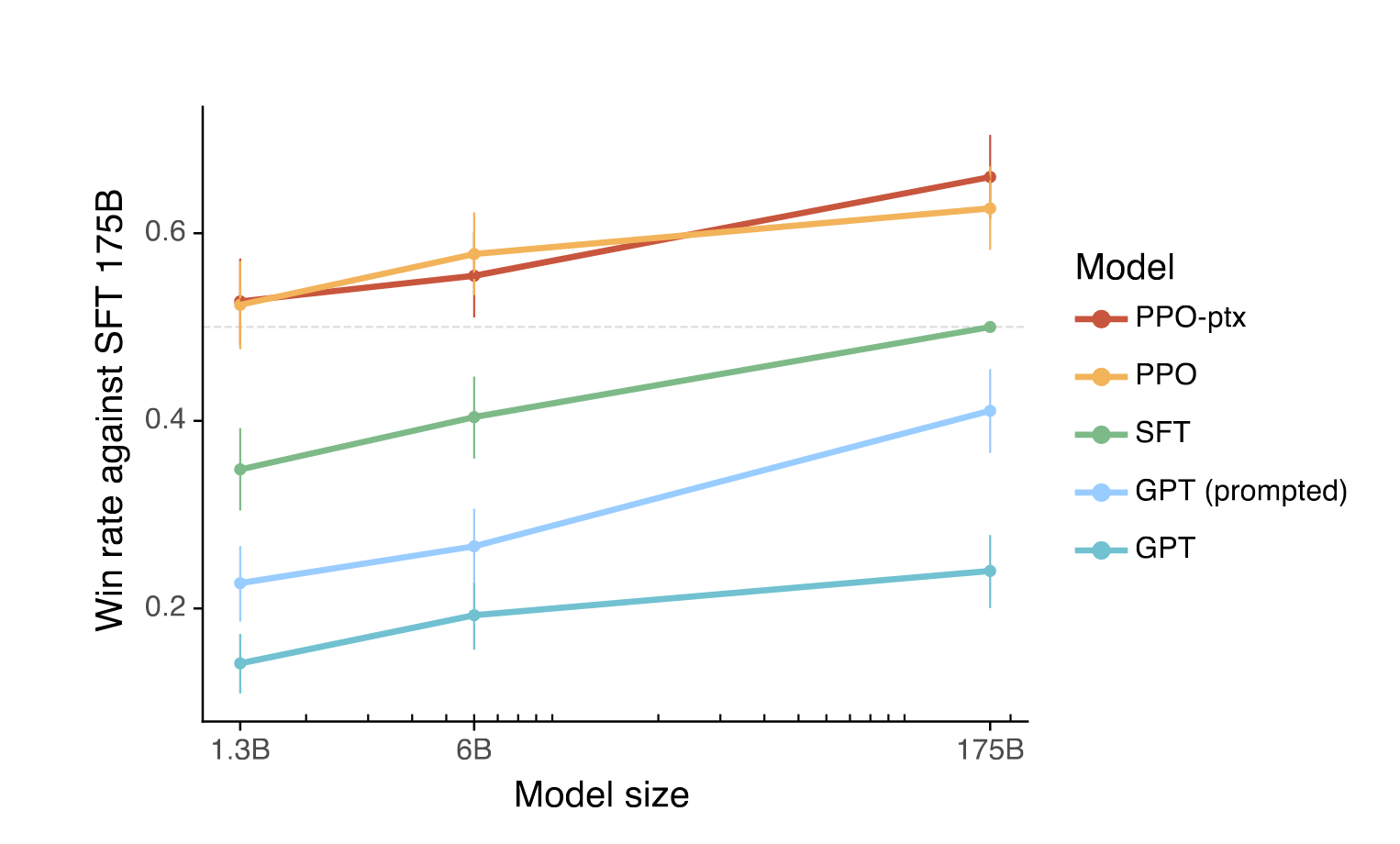
-
Architecture: While all the models in the GPT series are based on the decoder component of the Transformer architecture, there have been some modifications to the architecture over time. For example, GPT-2 introduced a novel positional encoding scheme, and GPT-3 incorporated sparse attention patterns from the Sparse Transformer architecture.
The maximum input sequence length (counted in tokens, which can be thought of as word fragments) supported by the models also increased from 512 in GPT-1, to 1024 in GPT-2, to 2048 in GPT-3, and 4096 in ChatGPT.
On average, one token is ¾ of an English word, which means the most words you could prompt these models with has increased from about 384 to over 3000.
-
Training Data Size: The amount and quality of training data have also increased over time.
-
GPT-1 was trained on the BooksCorpus dataset, containing over 7,000 unique unpublished books from a variety of genres. The data size was about 1 GB.
-
GPT-2 was trained on WebText, which the authors created specifically for their research. It is created by scraping all Reddit links with at least 3 karma. This resulted in slightly over 8 million documents for a total of 40 GB of text.
-
GPT-3 was trained primarily on the Common Crawl dataset, but the authors filtered it significantly to improve data quality. The data size after filtering came down to about 570 GB. In addition, the training set included an expanded version of WebText, Books1 and Books2, and the entirety of English-language Wikipedia.
-
-
Training Methodology: Before InstructGPT, the only objective while training GPT models was performing well on next-word prediction. InstructGPT and ChatGPT are fine tuned versions of GPT-3, so they are not trained on large, fresh corpora of text.
Instead, they use a combination of:
-
prompts gathered from real users of GPT-3 Playground
-
human labelers
-
reinforcement learning (specifically RLHF)
to reduce harmful and untruthful content and align the model closer to the task requested by the prompter. The following image from the InstructGPT paper summarizes the process.
-
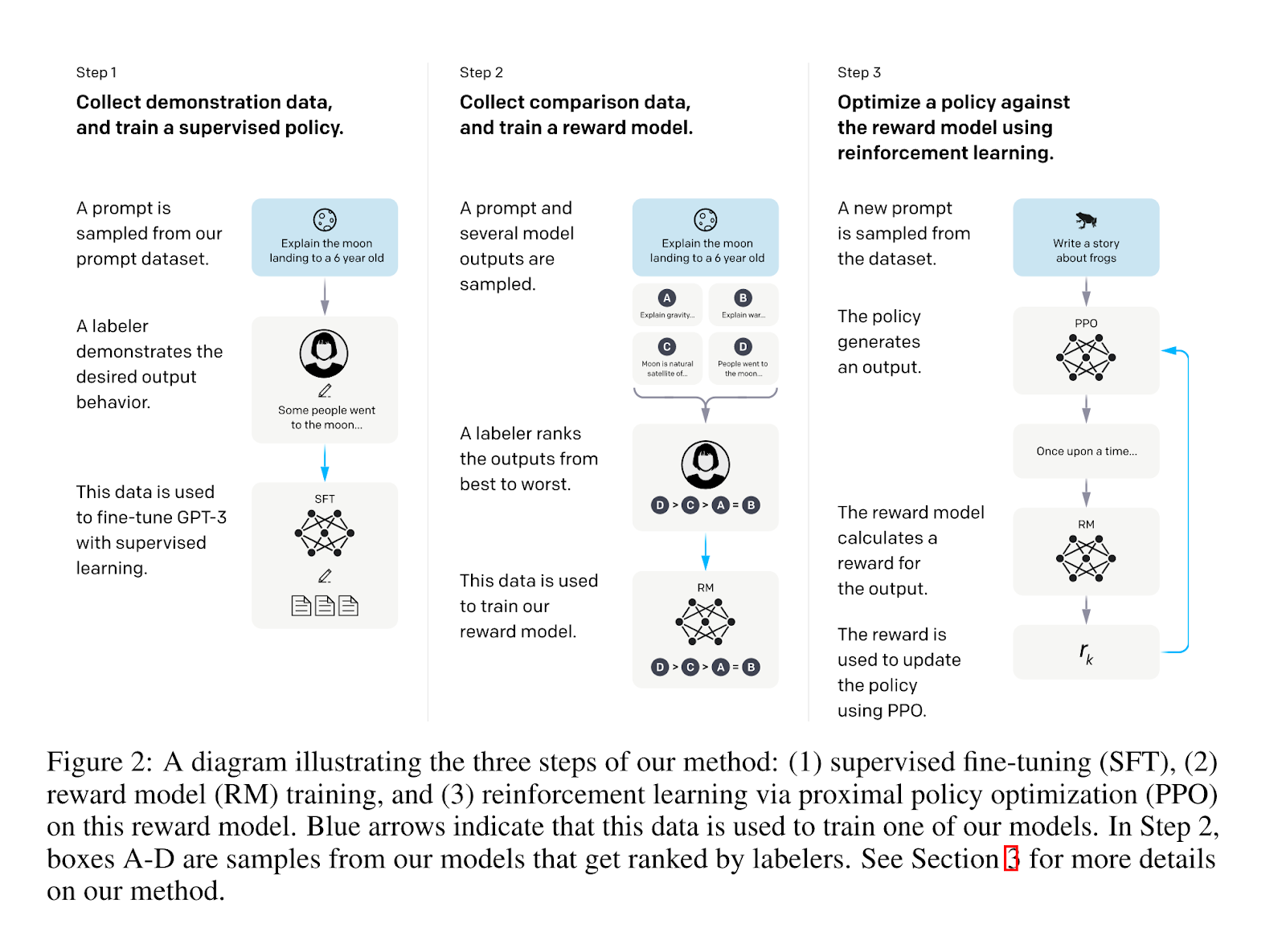
What exactly should I expect ChatGPT to know about?
We know that GPT-3.5 finished training in early 2022, and so it was trained on pre-2022 data. Therefore ChatGPT has limited knowledge of the world and events after 2021.
Note that in their FAQs, OpenAI uses the phrase limited knowledge. This is because even though the model itself has (purportedly) not been retrained since early-2022, it is constantly being fine-tuned by the RLHF mentioned previously, in an attempt to patch bugs and remove newly exposed vulnerabilities.
This process ends up leaking some new information into the model, which is probably the reason why we have occasionally been seeing behavior like this - ChatGPT knows Elon Musk is Twitter’s CEO, despite saying its learning cutoff was in 2021.
How can ChatGPT understand / generate novel text that is not present in its training data?
This super-ability is a result of the ingenious way in which the GPT models tokenize text - a technique called Byte-Pair Encoding.
Oversimplifying quite a bit, we can imagine that ChatGPT isn’t just limited to predicting the next word in a sequence - it can predict the next character too. And it can more or less freely choose to do either of those.
So if you prompt ChatGPT with a word it knows (i.e. a word in its vocabulary) such as “president”, it will represent it as a single token.
When prompted with longer and/or less frequently used words (or even non-words), such as “indirectly”, it will split the word into tokens (in-direct-ly) that are in its vocabulary. Note the semantic significance of the split in this case.
During generation, if it needs to generate a word that is not in its vocabulary (imagine the prompt “Repeat the word xyzzy back to me”), in the worst case it can do so by joining single-character tokens (x-y-z-z-y) together, one at a time. [3]
You can play with the tokenizer here to see how GPT models tokenize words.
How does ChatGPT remember what we’ve been talking about, and how much can it remember?
Disclaimer: ChatGPT is both a model and a web application powered by that model. Though we can speculate fairly confidently about the model, the web application can have several features engineered on top of the model that OpenAI has not revealed to the world. I make no comments about any such “tacked-on” features.
ChatGPT doesn’t actually “remember” anything. Since at its core, it is just a Transformer model with a max input sequence length of 4096 tokens, each time the model generates some text, it is only going off of what it received as its 4k token input. Every time you enter a prompt into ChatGPT, it feeds in as much of the current conversation as it can back into the model, and generates fresh response text.
OpenAI has made no information available about if and how ChatGPT attempts to tackle conversations that are longer in length than 4096 tokens, though theories abound on the internet:
A. Maybe ChatGPT simply uses a sliding window of 4096 tokens, keeping only the latest 4096 tokens in context?
B. Maybe it always retains the start of the conversation, and fills the rest of the context with the most recent N tokens?
C. Maybe it uses its own summarization capabilities to summarize previous bits of conversation, to be able to represent the entire conversation context within 4096 tokens?
I have seen no evidence to suggest B and C are possibilities, and A seems most likely. However, people online seem to have differing experiences, some suggesting that the context window might be larger.
My experiments seem to indicate that A is correct, and the window size is 4096 tokens after all.
Meta’s Blender Bot and some other offerings on the market do offer chatbots with effectively infinite context.
Does ChatGPT transfer information across separate chats? If yes, how (browser cookies, server side logging, etc.)?
According to OpenAI’s own statements, ChatGPT does not use context from previous chats.
Does ChatGPT explicitly decompose prompts into the task, instructions, context, examples, etc.? If yes, how?
Prompts to ChatGPT can contain (among other things) a combination of the following components:
-
the task to be performed (summarization, composition, question-answering, etc.)
-
instructions specifying how to do the task (no more than 600 words, use the style of Shakespeare, etc.)
-
context around the task (the full text that needs to be summarized, the question that needs to be answered, etc.)
-
examples of the task being done. These are also known as shots, commonly seen in the phrases “zero-shot”, “one-shot”, and “few-shot” learning.
According to the literature, GPT-like models do not explicitly decompose the prompt. All the segmentation and representation happens within the weights and biases of the giant neural networks. Since GPT-3 / InstructGPT perform similarly to ChatGPT on prompt completion without any of its bells and whistles, there is no reason to believe that there is an extra segmentation component in ChatGPT.
This is the reason why the GPT-2 paper was titled “Language Models are Unsupervised Multitask Learners” - during training, these models are never given a certain task to perform. They simply figure things out by modeling the training corpus extremely well.
Also of interest is the fact that the GPT-3 paper was called “Language Models are Few-Shot Learners”. In this paper, the researchers moved their focus from fine-tuning on specific tasks to figuring out how well a sufficiently large language model can perform on novel tasks, with a few examples of the task provided as part of the prompt itself. They realized that GPT-3 was really good at this. Check out the appendix for a graphic from the paper explaining the difference.
Does the order in which the task, instructions, context, etc. are provided in the prompt matter?
Not really, though it is hard to provide solid proof of this. It does appear that the order does not matter, as long as all the pieces of information are present and written coherently.
The following prompts yield similar responses:
-
“Summarize the following essay” - <essay> - “limit the summary to 150 words”
-
<essay> - “Summarize the essay above in less than 150 words”
-
“Give a 150 word summary of the following essay” - <essay>
There can, however, always be statistical anomalies in favor of more commonly used sentence and paragraph constructions.
Appendix
My Experiment with ChatGPT Context Windows
I asked ChatGPT to remember the word “ampersand”, then fed it a small block of Lorem Ipsum text and asked it to repeat the word.
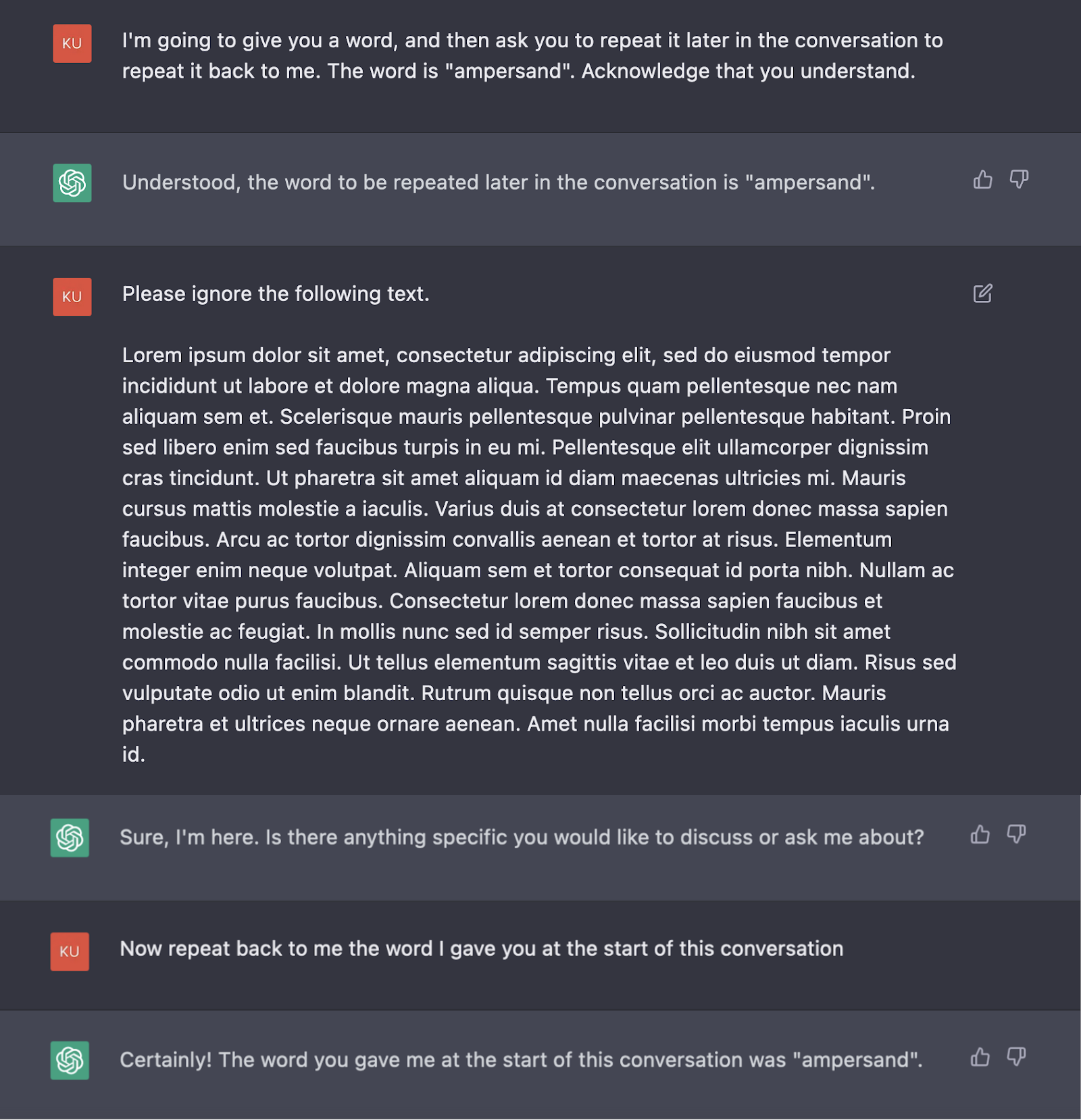
ChatGPT was successful!
Next I fed it a much larger block of text (4098 tokens to be precise, which is larger than its 4096 token context window), and asked it to repeat the word again.

ChatGPT was… not so successful.
Few-Shot Learning

Further Reading
What Is ChatGPT Doing … and Why Does It Work?—Stephen Wolfram Writings
Footnotes
-
Fun fact: If you ask ChatGPT these questions, it will hallucinate up alarmingly inaccurate answers. ↩
-
Just like WW1 was called The Great War before WW2 came along, GPT-1 used to be GPT. ↩
-
Interestingly, xyzzy is actually tokenized as xy-zzy. This is probably because -xy and -zzy are common word suffixes (proxy, fizzy). ↩